筆者對各大廠商CTR預(yù)估模型的優(yōu)缺點進行對比,并結(jié)合自身的使用和理解,梳理出一條CTR預(yù)估模型的發(fā)展脈絡(luò),希望幫助到有需要的同學(xué)。
1. 背景
2. LR 海量高緯離散特征 (廣點通精排)
3. GBDT 少量低緯連續(xù)特征 (Yahoo & Bing)
4. GBDT+LR (FaceBook)
5. FM+DNN (百度鳳巢)
6. MLR (阿里媽媽)
7. FTRL_Proximal (Google)
1. 背景
眾所周知,廣告平臺的最終目標是追求收益最大化,以 CPC 廣告為例,平臺收益既與 CPC 單價有關(guān),又與預(yù)測 CTR 有關(guān)。在排序的時候,CPC 可以認為是一個確定的值,所以這里的關(guān)鍵是預(yù)測用戶的點擊率 pCTR。



2.1 正則化
為了防止過擬合,通常會在損失函數(shù)后面增加懲罰項 L1 正則或者 L2 正則:
L1 正則化是指權(quán)值向量 w 中各個元素的絕對值之和,通常表示為||w||1;
L2 正則化是指權(quán)值向量 w 中各個元素的平方和然后再求平方根,通常表示為||w||2。
其中,L1 正則可以產(chǎn)生稀疏性,即讓模型部分特征的系數(shù)為 0。這樣做有幾個好處:首先可以讓模型簡單,防止過擬合;還能選擇有效特征,提高性能。
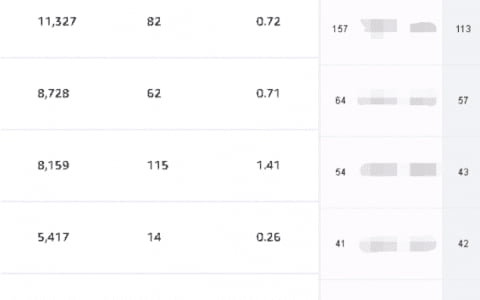
如上圖:最優(yōu)解出現(xiàn)在損失函數(shù)的等值線和約束函數(shù) L1 相切的地方,即凸點,而菱形的凸點往往出現(xiàn)在坐標軸上(系數(shù) w1 或 w2 為 0),最終產(chǎn)生了稀疏性。
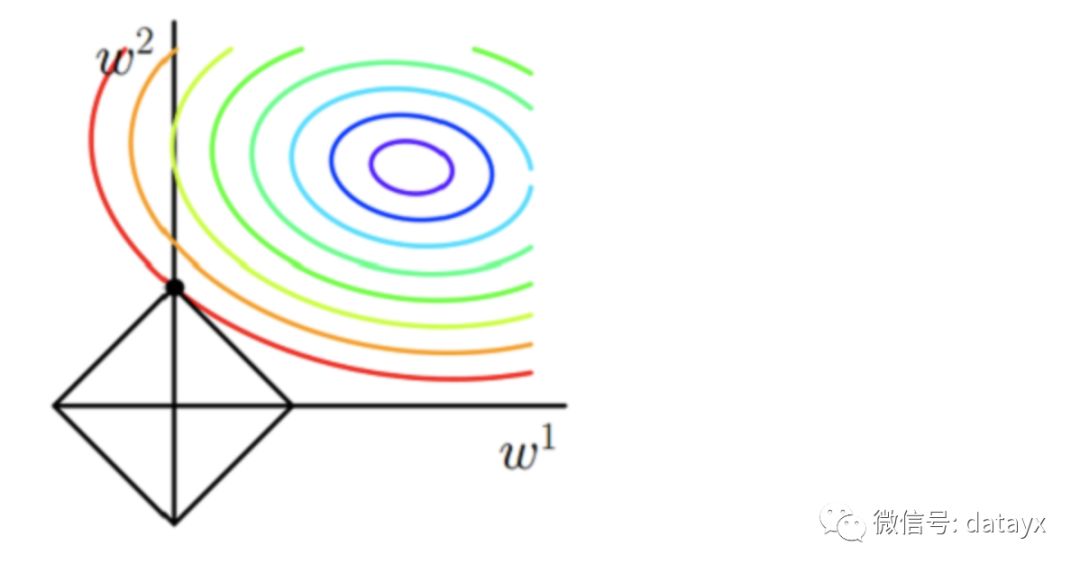
L2 正則通過構(gòu)造一個所有參數(shù)都比較小的模型,防止過擬合。但 L2 正則不具有稀疏性,原因如下圖,約束函數(shù) L2 在二維平面下為一個圓,與等值線相切在坐標軸的可能性就小了很多。
2.2 離散化
LR 處理離散特征可以得心應(yīng)手,但處理連續(xù)特征的時候需要進行離散化。通常連續(xù)特征會包含:大量的反饋 CTR 特征、表示語義相似的值特征、年齡價格等屬性特征。
以年齡為例,可以用業(yè)務(wù)知識分桶:用小學(xué)、初中、高中、大學(xué)、工作的平均年齡區(qū)間做分桶;也可以通過統(tǒng)計量分桶,使各個分桶內(nèi)的數(shù)據(jù)均勻分布。
反饋 CTR 特征的離散化,一般通過統(tǒng)計量分桶,但在桶的邊界往往會出現(xiàn)突變的問題,比如兩個桶分別為 0.013~0.015、0.015~0.018,在邊界左右的值 0.01499 和 0.01501 會帶來完全不同的效果。(這里給 GBDT LR 埋下一個伏筆)。
2.3 特征組合
LR 由于是線性模型,不能自動進行非線性變換,需要大量的人工特征組合。以 id 類特征為例,用戶 id 往往有上億維(one-hot),廣告 id 往往有上百萬維,特征組合會產(chǎn)生維度爆炸。
廣告特征里往往有三類維度(a,u,c),分別是廣告類特征、用戶類特征、上下文類特征。這三類特征內(nèi)部兩兩組合、三三組合,外部再兩兩組合、三三組合就產(chǎn)生了無限多種可能性。所以在 CTR 預(yù)估模型的早期,主要工作就是在做人工特征工程。人工特征工程不但極為繁瑣,還需要大量的領(lǐng)域知識和試錯。
2.4 優(yōu)缺點
優(yōu)點:由于 LR 模型簡單,訓(xùn)練時便于并行化,在預(yù)測時只需要對特征進行線性加權(quán),所以性能比較好,往往適合處理海量 id 類特征,用 id 類特征有一個很重要的好處,就是防止信息損失(相對于范化的 CTR 特征),對于頭部資源會有更細致的描述。
缺點:LR 的缺點也很明顯,首先對連續(xù)特征的處理需要先進行離散化,如上文所說,人工分桶的方式會引入多種問題。另外 LR 需要進行人工特征組合,這就需要開發(fā)者有非常豐富的領(lǐng)域經(jīng)驗,才能不走彎路。這樣的模型遷移起來比較困難,換一個領(lǐng)域又需要重新進行大量的特征工程。
3. GBDT 少量低緯連續(xù)特征 (Yahoo & Bing)
GBDT(Gradient Boosting Decision Tree)[2]是一種典型的基于回歸樹的 boosting 算法。學(xué)習(xí) GBDT,只需要理解兩方面:
a. 梯度提升(Gradient Boosting):每次建樹是在之前建樹損失函數(shù)的梯度下降方向上進行優(yōu)化,因為梯度方向(求導(dǎo)) 是函數(shù)變化最陡的方向。不斷優(yōu)化之前的弱分類器,得到更強的分類器。每一棵樹學(xué)的是之前所有樹結(jié)論和的殘差。
b. 回歸樹(Regression Tree):注意,這里使用的是回歸樹而非決策樹,通過最小化 log 損失函數(shù)找到最靠譜的分支,直到葉子節(jié)點上所有值唯一 (殘差為 0),或者達到預(yù)設(shè)條件(樹的深度)。若葉子節(jié)點上的值不唯一,則以該節(jié)點上的平均值作為預(yù)測值。
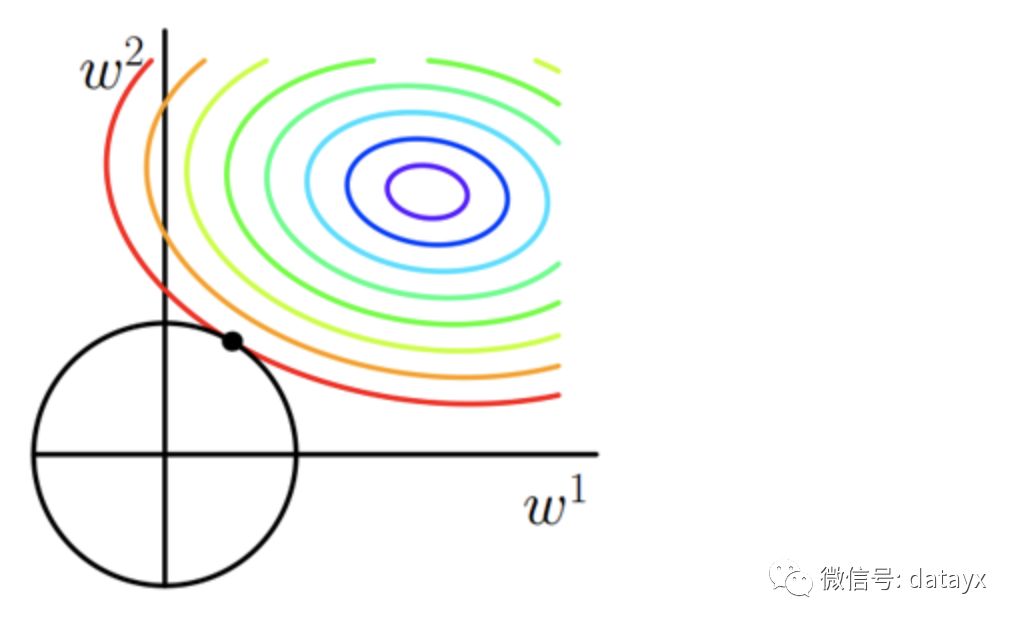
核心問題 1:回歸樹怎么才能越來越好?
最直觀的想法,如果前一輪有分錯的樣本,那邊在后面新的分支只需提高這些分錯樣本的權(quán)重,讓沒學(xué)好的地方多學(xué)一學(xué)。這種方法在數(shù)學(xué)上可以用殘差來很好的解決,比如上圖中,第一輪訓(xùn)練后殘差向量為(-1, 1, -1, 1),第二輪訓(xùn)練就是為了消除殘差,即這些分錯的樣本,當殘差為 0 或者達到停止條件才停止。
那么哪里體現(xiàn)了Gradient呢?其實回到第一棵樹結(jié)束時想一想,無論此時的 cost function 是什么,是均方差還是均差,只要它以誤差作為衡量標準,殘差向量(-1, 1, -1, 1) 都是它的全局最優(yōu)方向,這就是 Gradient。
核心問題 2:如何將多個弱分類器組合成一個強分類器?
通過加大分類誤差率較小的弱分類器的權(quán)重,通過多棵權(quán)重不同的樹(能者多勞)進行打分,最終輸出回歸預(yù)測值。
3.1 特征工程
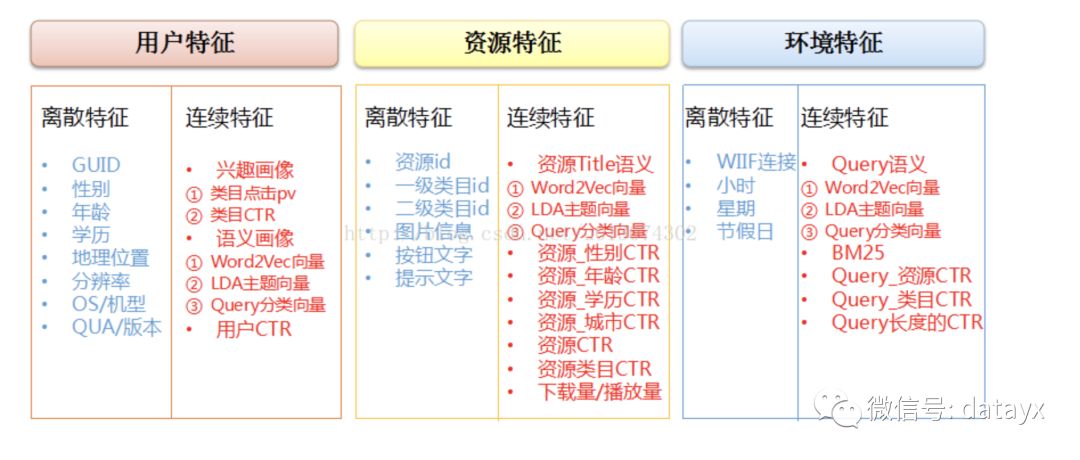
由于 GBDT 不善于處理大量 id 類離散特征(后文會講到),但是卻善于處理連續(xù)的特征,一般的做法是用各種 CTR 反饋特征來做交叉,來范化的表達信息。在這種情況下,信息會大量存在于動態(tài)特征中,而少量存在于模型中(對比 LR,信息幾乎都存在于模型中)。下圖是作者為搜索廣告的 GBDT 模型設(shè)計的特征,讀者可供參考。
3.2 優(yōu)缺點
優(yōu)點:我們可以把樹的生成過程理解成自動進行多維度的特征組合的過程,從根結(jié)點到葉子節(jié)點上的整個路徑(多個特征值判斷),才能最終決定一棵樹的預(yù)測值。另外,對于連續(xù)型特征的處理,GBDT 可以拆分出一個臨界閾值,比如大于 0.027 走左子樹,小于等于 0.027(或者 default 值)走右子樹,這樣很好的規(guī)避了人工離散化的問題。
缺點:對于海量的 id 類特征,GBDT 由于樹的深度和棵樹限制(防止過擬合),不能有效的存儲;另外海量特征在也會存在性能瓶頸,經(jīng)筆者測試,當 GBDT 的 one hot 特征大于 10 萬維時,就必須做分布式的訓(xùn)練才能保證不爆內(nèi)存。所以 GBDT 通常配合少量的反饋 CTR 特征來表達,這樣雖然具有一定的范化能力,但是同時會有信息損失,對于頭部資源不能有效的表達。
4. GBDT LR (FaceBook)
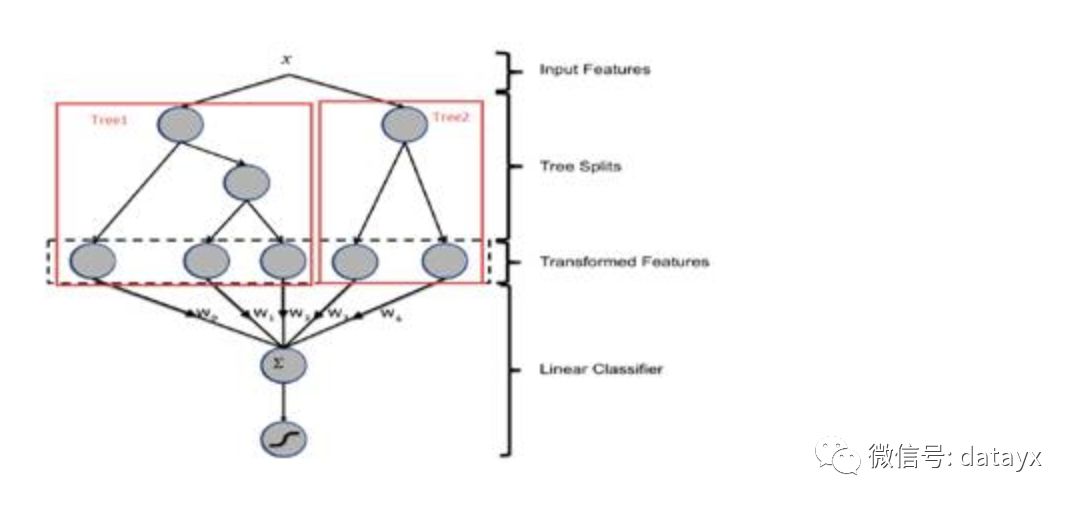
Facebook 在 2014 年發(fā)表文章介紹了通過 GBDT 解決 LR 的特征組合問題[3],其主要實現(xiàn)原理是:
訓(xùn)練時,GBDT 建樹的過程相當于自動進行的特征組合和離散化,然后從根結(jié)點到葉子節(jié)點的這條路徑就可以看成是不同特征進行的特征組合,用葉子節(jié)點可以唯一的表示這條路徑,并作為一個離散特征傳入 LR 進行二次訓(xùn)練。
預(yù)測時,會先走 GBDT 的每棵樹,得到某個葉子節(jié)點對應(yīng)的一個離散特征(即一組特征組合),然后把該特征以 one-hot 形式傳入 LR 進行線性加權(quán)預(yù)測。
4.1 改進
Facebook 的方案在實際使用中,發(fā)現(xiàn)并不可行,因為廣告系統(tǒng)往往存在上億維的 id 類特征(用戶 guid10 億維,廣告 aid 上百萬維),而 GBDT 由于樹的深度和棵樹的限制,無法存儲這么多 id 類特征,導(dǎo)致信息的損失。有如下改進方案供讀者參考:
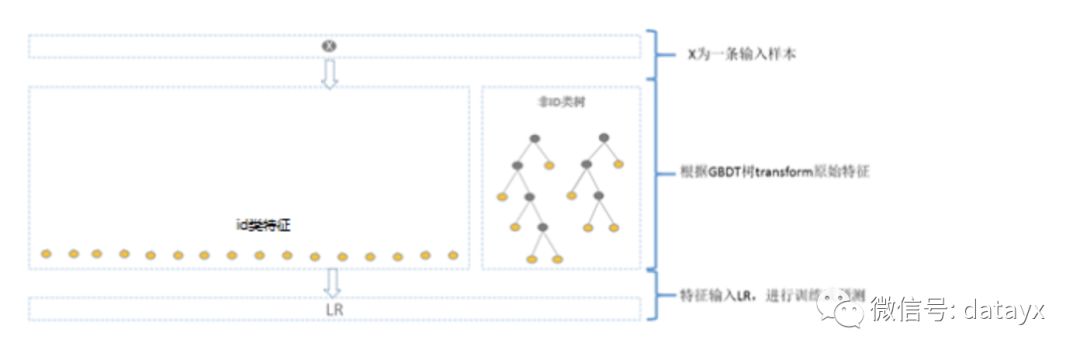
方案一:GBDT 訓(xùn)練除 id 類特征以外的所有特征,其他 id 類特征在 LR 階段再加入。這樣的好處很明顯,既利用了 GBDT 對連續(xù)特征的自動離散化和特征組合,同時 LR 又有效利用了 id 類離散特征,防止信息損失。
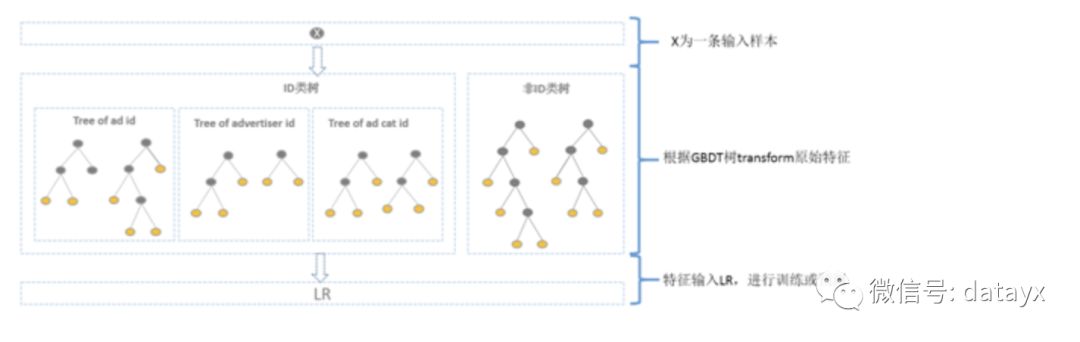
方案二:GBDT 分別訓(xùn)練 id 類樹和非 id 類樹,并把組合特征傳入 LR 進行二次訓(xùn)練。對于 id 類樹可以有效保留頭部資源的信息不受損失;對于非 id 類樹,長尾資源可以利用其范化信息(反饋 CTR 等)。但這樣做有一個缺點是,介于頭部資源和長尾資源中間的一部分資源,其有效信息即包含在范化信息(反饋 CTR) 中,又包含在 id 類特征中,而 GBDT 的非 id 類樹只存的下頭部的資源信息,所以還是會有部分信息損失。
4.2 優(yōu)缺點
優(yōu)點:GBDT 可以自動進行特征組合和離散化,LR 可以有效利用海量 id 類離散特征,保持信息的完整性。
缺點:LR 預(yù)測的時候需要等待 GBDT 的輸出,一方面 GBDT在線預(yù)測慢于單 LR,另一方面 GBDT 目前不支持在線算法,只能以離線方式進行更新。
5. FM DNN (百度鳳巢)
隨著深度學(xué)習(xí)的逐漸成熟,越來越多的人希望把深度學(xué)習(xí)引入 CTR 預(yù)估領(lǐng)域,然而由于廣告系統(tǒng)包含海量 id 類離散特征,如果全用 one-hot 表示,會產(chǎn)生維度爆炸,DNN 不支持這么多維的特征。目前工業(yè)界方案是 FNN[4],即用 FM 做 Embedding,DNN 做訓(xùn)練。
FM(factorization machines)[5]的目標函數(shù)如下:
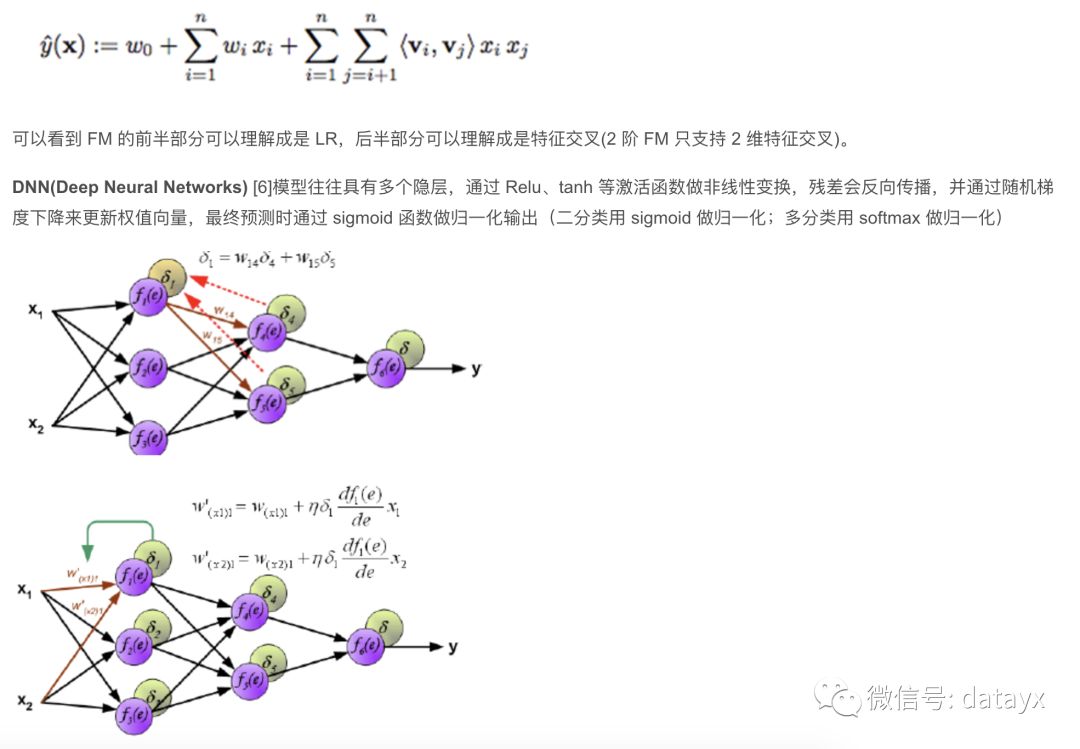
FM DNN 的具體做法是:
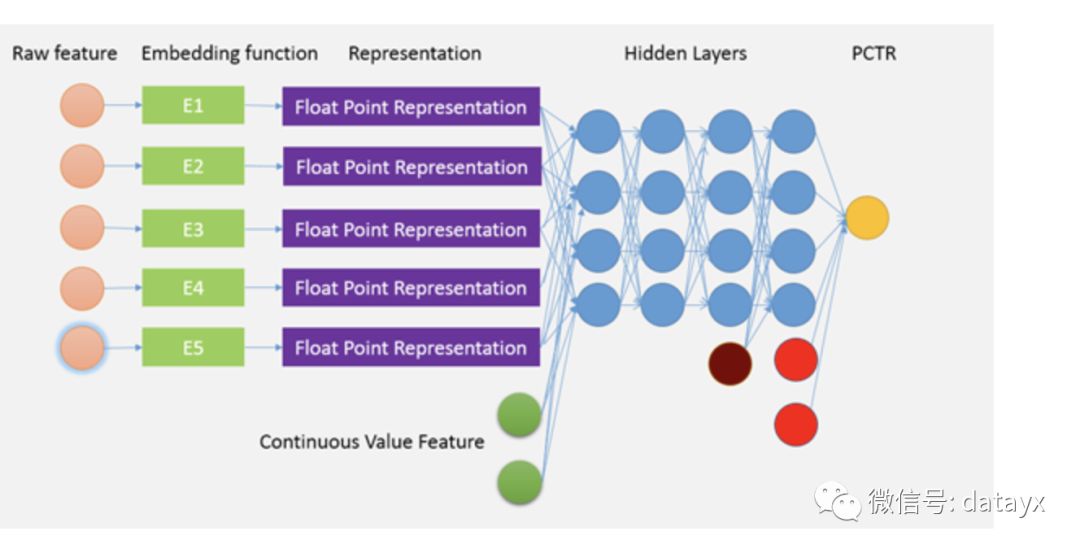
對于離散特征,先找到其對應(yīng)的 category field,并用 FM 做 embedding,把該 category field 下的所有特征分別投影到這個低維空間中。以用戶 query 為例,如果用 one-hot 可能有數(shù)十億維,但是如果我們用 FM 編碼,就可以把所有的 query 都映射到一個 200 維的向量連續(xù)空間里,這就大大縮小了 DNN 模型的輸入。
而對于連續(xù)特征,由于其特征維度本來就不多,可以和 FM 的輸出一同輸入到 DNN 模型里進行訓(xùn)練。
6.1 優(yōu)缺點
優(yōu)點:FM 可以自動進行特征組合,并能把同一 category field 下的海量離散特征投影到一個低緯的向量空間里,大大減少了 DNN 的輸入。而 DNN 不但可以做非線性變換,還可以做特征提取。
缺點:由于 2 階FM 只支持 2 維的特征交叉(考慮性能的因素常用 2 階 FM),所以不能像 GBDT 那樣做到 10 維的特征組合。另外 DNN 模型出于調(diào)參復(fù)雜和性能不高的原因,并不適用于中小型業(yè)務(wù)。所以在工業(yè)界使用的不多。
6. MLR (阿里媽媽)
前一陣子阿里巴巴的廣告部阿里媽媽公布了其 MLR(mixed logistic regression) 模型 [7],MLR 是 LR 的一個改進, 它采用分而治之的思想,用分片線性的模式來擬合高維空間的非線性分類面。
簡單來說,MLR 就是聚類 LR,先對樣本空間進行分割,這里有一個超參數(shù) m,用來代表分片的個數(shù),當 m=1 時自動淪為普通的 LR;當 m 越大,擬合能力越強;當然隨著 m 增大,其所需要的訓(xùn)練樣本數(shù)也不斷增大,性能損耗也不斷增加。阿里的實驗表明,當 m=12 時,表現(xiàn)最好。

上圖可以看到,對于這種高緯空間的非線性分類面,用 MLR 的效果比 LR 好。
6.1 優(yōu)缺點
優(yōu)點:MLR 通過先驗知識對樣本空間的劃分可以有效提升 LR 對非線性的擬合能力,比較適合于電商場景,如 3C 類和服裝類不需要分別訓(xùn)練各自不同的 LR 模型,學(xué)生人群和上班族也不需要單獨訓(xùn)練各自的 LR,在一個 LR 模型中可以搞定。模型的遷移能力比較強。
缺點:MLR 中超參數(shù) m需要人工去調(diào),另外還是有 LR 共性的缺點,如需要人工特征組合和人工離散化分桶等。
7. FTRL_Proximal (Google)
對于 LR 靜態(tài)特征這種模型,信息主要存儲在模型中(相比 GBDT 動態(tài)特征,信息既存儲在模型中又存儲在動態(tài)特征里),所以為了讓模型更加快速的適應(yīng)線上數(shù)據(jù)的變化,google 率先把在線算法 FTRL 引入 CTR 預(yù)估模型 [8]。
online 算法其實并不復(fù)雜,batch 算法需要遍歷所有樣本才能進行一輪參數(shù)的迭代求解(如隨機梯度下降),而 online 算法可以每取一個訓(xùn)練樣本,就對參數(shù)進行一次更新,大大提升了效率。但這樣做也引入了一個問題,模型迭代不是沿著全局的梯度下降,而是沿著某個樣本的梯度進行下降,這樣即使用 L1 正則也不一定能達到稀疏解。
FTRL 是在傳統(tǒng)的在線算法如 FOBOS 和 RDA 的基礎(chǔ)上做了優(yōu)化,它采用和 RDA 一樣的 L1 正則,同時和 FOBOS 一樣會限制每次更新的距離不能太遠。所以它在稀疏性和精確度上要優(yōu)于 RDA 和 FOBOS[9]。

7.1 優(yōu)缺點
優(yōu)點:FTRL 可以在線訓(xùn)練,這樣使 LR 存儲于模型中的信息可以得到快速的更新。另外 FTRL 也具有不錯的稀疏性和精確度,可以減少內(nèi)存占用防止過擬合。最后 FTRL_Proximal 還支持動態(tài)的學(xué)習(xí)率,可以對不同完整性的特征采用不同的步長進行梯度下降。
缺點:FTRL 同樣具有 LR 的缺點,需要人工特征工程和人工離散化分桶。
作者:Alan船長 來源:Alan船長
本文為作者獨立觀點,不代表出海筆記立場,如若轉(zhuǎn)載請聯(lián)系原作者。