?
作為一名digital marketer, 西西莉亞一直對Facebook廣告背后的運(yùn)作機(jī)制非常感興趣。
網(wǎng)上可以查找到很多關(guān)于Facebook廣告競價的算法的文章,卻因?yàn)槲幢还_,很少有關(guān)于廣告投放中推薦受眾的算法的討論。
西西莉亞之前做過機(jī)器學(xué)習(xí)的課題,再加上對AdTech的一些小小的心得和研究,決定自己動手豐衣足食,親自上陣寫一寫Facebook廣告背后的故事。?
這是一篇關(guān)于Facebook廣告(推薦受眾)算法的技術(shù)分析貼。目的在于和大家探討一下,機(jī)器學(xué)習(xí)和人工智能在算法中的作用,揭開“黑盒”機(jī)制的神秘面紗。
西西莉亞會盡量講的通俗一些,而且只挑選對廣告投手們比較有用的部分。太細(xì)節(jié)太深度的內(nèi)容,我們還是留給學(xué)術(shù)界吧。
1 社交網(wǎng)絡(luò)與人工智能
首先,Cecilia覺得有必要簡單的區(qū)分下“人工智能(AI)”和“機(jī)器學(xué)習(xí)(Machine Learning)”兩個概念。人工智能最近火的不行,它其實(shí)是一個比較寬泛的名詞,指的是所有可以用計算機(jī)模仿人類的行為并且代替人類執(zhí)行人工作業(yè)。
機(jī)器學(xué)習(xí)是人工智能的實(shí)踐和應(yīng)用,具體是通過大數(shù)據(jù)來訓(xùn)練算法和數(shù)據(jù)模型,從而更加準(zhǔn)確地對新的(未知)數(shù)據(jù)及指令作出預(yù)測和判斷。再往下走,又會是深度學(xué)習(xí)(Deep Learning)等,作為廣告投手不需要知道那么學(xué)術(shù)和專業(yè)的東西。
本文中西西莉亞主要用的名詞“機(jī)器學(xué)習(xí)”,但是大家要知道人工智能和機(jī)器學(xué)習(xí)某些情況下其實(shí)指的是一回事。人工智能的概念其實(shí)很早就被提出來了,大家還記得經(jīng)典電影《黑客帝國》嗎?電影中就講到人類和智商卓越的機(jī)器之間的斗爭。
但是為什么近幾年才大火?
因?yàn)槿斯ぶ悄苄枰揽繑?shù)據(jù)驅(qū)動,而早前的計算機(jī)是沒有辦法高速處理海量數(shù)據(jù)信息的。
直到硬件產(chǎn)業(yè)的瓶頸被突破,海量數(shù)據(jù)并行處理的CPU甚至更強(qiáng)大的GPU面世,AI終于可以擺脫束縛,盡情地汲取所有可以獲得的信息,發(fā)展一日千里。
所以可以簡單粗暴的說,沒有數(shù)據(jù),就沒有人工智能。
那么,數(shù)據(jù)從哪里來?
除了專業(yè)的研究數(shù)據(jù)采集,對于像Facebook這樣的社交網(wǎng)絡(luò),每天有上億的用戶自發(fā)地生成各種數(shù)據(jù)(UGC):照片、影片、語音、文字、社交互動等等。除此之外,F(xiàn)acebook還可以通過你的瀏覽器的cookie來追蹤你在互聯(lián)網(wǎng)上的一切行為。比如你瀏覽過哪些網(wǎng)站?你搜索過哪些內(nèi)容?你產(chǎn)生過哪些購買行為?
在Facebook的官網(wǎng)中有這樣一段話:
“ We use cookies to help us show ads and to make recommendations for businesses and other organizations to people who may be interested in the products, services or causes they promote.”
所以,F(xiàn)acebook主要是通過追蹤瀏覽器的cookie來收集用戶的數(shù)據(jù),進(jìn)而對用戶的喜好和行為進(jìn)行預(yù)測,選擇最適合的廣告呈現(xiàn)在用戶面前。
同時Facebook又用cookie來判斷控制廣告的投放,以及評估廣告的質(zhì)量。
比如確保該廣告出現(xiàn)在同一個用戶的時間線上不超過X次(impression)。再比如該用戶是否與廣告產(chǎn)生了交互行為(點(diǎn)擊、留言、點(diǎn)贊、購買。。。等等)。
作為互聯(lián)網(wǎng)時代的小尖兵,又穩(wěn)坐社交網(wǎng)絡(luò)頭把交椅,F(xiàn)acebook擁有這個世界上最值錢的數(shù)據(jù):全世界超過20億的活躍用戶信息。
但凡走過,必留下痕跡。
你在互聯(lián)網(wǎng)上的一切行為都被轉(zhuǎn)換成計算機(jī)可以讀懂的數(shù)據(jù),進(jìn)而為之所用。
2 機(jī)器學(xué)習(xí)算法在廣告受眾推薦上的應(yīng)用
Facebook ad算法是預(yù)測性算法(Predictive Algorithm)。
簡單的說,機(jī)器學(xué)習(xí)的算法通過“學(xué)習(xí)”廣告投放得到的反饋(歷史數(shù)據(jù)),對新的廣告投放效果進(jìn)行預(yù)測。
機(jī)器學(xué)習(xí)算法的兩大類別:回歸算法(Regression)和分類算法(classification)。
回歸算法的結(jié)果是一些連續(xù)的值,比如一元二次方程里的一條直線,任意一個橫坐標(biāo)的X值,都可以找到一個對應(yīng)的Y值。而分類算法的輸出結(jié)果并不是連續(xù)的,而更像是一段又一段的區(qū)間。
舉個例子?,當(dāng)你問“這個用戶看到廣告后會不會點(diǎn)擊購買我的產(chǎn)品”?
通過分析,分類算法會告訴你,“Yes”還是“No”。
但是回歸算法會告訴你“只有68.59%的可能性會買,也有31.41%的可能性不會買”。
實(shí)際上,兩種算法并不是完全無法不兼容彼此的。
比如你在回歸算法的輸出層規(guī)定區(qū)間,“低于60%的值輸出No”,“不低于60%的輸出值為Yes”,這樣回歸算法就轉(zhuǎn)化為一個分類算法了。
不管使用哪種算法,在廣告投放領(lǐng)域,機(jī)器學(xué)習(xí)的核心都是通過分析audience的特性(demographics),來對TA的行為進(jìn)行預(yù)測。
用戶的每一個特性都是一個“自變量X”,而模型的輸出值,也就是“因變量Y”。
在回歸模型中,一個擬合的方程可以寫為:
Y = a*X1 + b*X2 - c*X3 +d*X4。。。
其中的X1/X2/X3/X4。。。可能代表的含義是:
- 性別、
- 年齡、
- 地址、
- 是否為Engaged shopper、
- 熱愛時尚、
- 喜歡小狗、
- 家里有剛出生的寶寶、
- 喜歡的顏色、
- 喜歡的音樂類型。。。
而a/b/-c/d。。。就是一些常量參數(shù),影響每個自變量的權(quán)重,也可以理解為,對因變量Y的影響程度高低。
因變量Y就代表你的廣告的目標(biāo)(objective)。
當(dāng)你選擇購買的時候,Y可能就代表這個用戶是否會轉(zhuǎn)化產(chǎn)生購買行為。當(dāng)你選擇的目標(biāo)是“視頻觀看(Video View)”時,Y就代表廣告推送給的這個人會不會耐心地看完你的廣告。
因?yàn)镕acebook廣告的算法對外界仍然是非公開的,是個黑盒(Black Box)。所以兩種算法其實(shí)都有可能,甚至可能是兩種算法的結(jié)合。
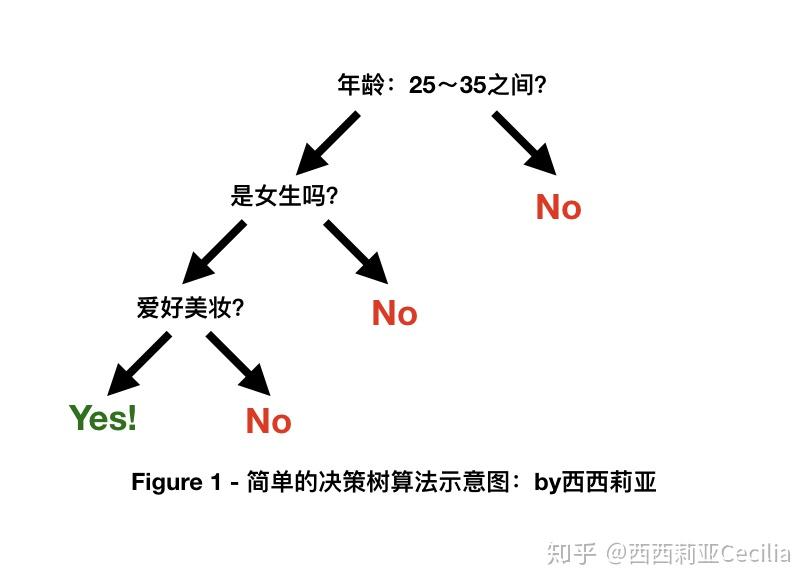
分類算法最簡單的就是“決策樹(Decision Tree)”。
決策樹是我認(rèn)為最直觀的一種機(jī)器學(xué)習(xí)算法。最簡單的決策樹是“二元決策樹”,即對每一個問題的回答只有兩個答案:“Yes”或者是“No”。
比如通過訓(xùn)練,F(xiàn)acebook ads的算法發(fā)現(xiàn),年齡在25~35歲、性別為“女”、愛好為“美妝和時尚”的受眾最容易對你的廣告產(chǎn)生轉(zhuǎn)化。
于是在此之后,對每一個新的“潛在受眾”,F(xiàn)acebook廣告算法都會問:
“
- 這個人的年齡是在25到35之間嗎?不是 -> PASS。是 -> 進(jìn)入下一題。
- 這個人是女的嗎?不是 -> PASS。是 -> 繼續(xù)下一題。
- 這個人有跟”美妝時尚相關(guān)的愛好嗎?“ 不是 -> PASS。是 -> 好噠!就是你了!美女,這里有個廣告你要不要了解一些?
”
接下來,靈魂畫手西西莉亞就用幾張直(超)觀(丑)的圖來解釋一下這幾個算法:
而回歸算法就略微復(fù)雜一些。
最簡單、也是最基礎(chǔ)的算法就是線形回歸(Linear Regression)。
假設(shè)我們只有一個自變量X,表示用戶的年齡。
因變量Y就是我們的廣告投放的目標(biāo)(Objective),比如說“購買”的可能性(概率)。
這個模型簡單粗暴,通過一個用戶的年齡來決定TA的購買行為。
根據(jù)廣告的投放經(jīng)驗(yàn),我們得到一些離散的點(diǎn),每個點(diǎn)可以被描述為(年齡,是否會購買),比如(25,Yes),(65,No), (30,Yes) 。
最后得到的曲線可能看起來像下面這張圖:
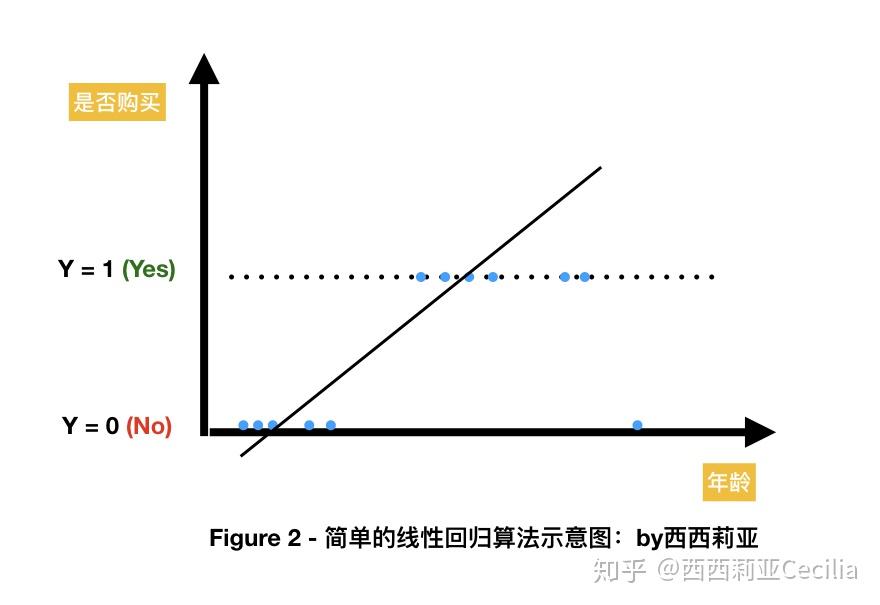
為了方便,我們把“Yes”和“No”都轉(zhuǎn)化為“1”和“0”。
【PS:其實(shí)這個例子不太好啦,因?yàn)橐蜃兞縔只有兩個值0和1,算是比較特例。
真實(shí)生活中Y往往也是個連續(xù)的值,比如觀看視頻的時常,或者消費(fèi)的金額。】
這個例子里,我們得到一個簡單的一元一次方程。
比如算法發(fā)現(xiàn),年齡越大,錢越多,購買力越強(qiáng)。
所以就會使勁兒把你的廣告盡可能的推送給上了年紀(jì)的人。
但是在現(xiàn)實(shí)生活中呢,我們的Target Audience的屬性才不會這么簡單只有年齡一個。
想想我們之前舉例說的那些X1/X2/X3/X4/X5。。。
每一個興趣,都在某一個維度上描述了某一個受眾。
比如,(“張三”,“男”,“30歲”,“單身”,“愛好擼貓”。。。)。
如果只有”年齡“一個維度,算法的擬合結(jié)果就給我們一條二維空間的”直線“。
而如果加上“性別”,我們有了2個自變量,算法就會給我們一個三維空間里的”面“。
再加上“感情狀況”,我們就有了3個自變量,算法就會給我們一個四維空間里的“體”。
至于五維、六維、七維。。。就是一些無法描述的“形狀”了。
每一個受眾,在算法的世界里,都是一個被拆解為多維向量代表的“點(diǎn)”。
而機(jī)器學(xué)習(xí),就是尋找在這浩瀚的空間中、無數(shù)個散落的點(diǎn)之間的聯(lián)系和規(guī)律。
算法的最終結(jié)果,就是一條劃過這個“多維宇宙”的、能穿起數(shù)量最多的“星星”的一條“線”。
這條“線”,就是機(jī)器學(xué)習(xí)的擬合(Fitting)結(jié)果。
【PS: 其實(shí)在多維空間上,這已經(jīng)不是一條“線”了。大家可以想象為投影在二維的坐標(biāo)軸上的一條線比較容易理解。】
當(dāng)機(jī)器學(xué)習(xí)得到穩(wěn)定的擬合結(jié)果后,對于每一個新的受眾,算法就會通過對TA的特征進(jìn)行分析,然后得到一個這個“點(diǎn)”距離預(yù)測的“線”之間的距離。
如果距離為零,代表這個受眾完美符合我們的所有條件,非常有可能轉(zhuǎn)化,F(xiàn)acebook ads的算法就會把廣告推送到他面前。
距離越遠(yuǎn),代表這個受眾越不可能轉(zhuǎn)化。算法于是自動跳過他而不會投放給他廣告。
Facebook廣告的Learning Phase就是在不斷的訓(xùn)練算法模型,尋找完美的擬合曲線。一旦學(xué)習(xí)結(jié)束,算法就會尋找目標(biāo)受眾中,距離曲線最近的點(diǎn)(潛在受眾)。
3 數(shù)據(jù)!數(shù)據(jù)!!數(shù)據(jù)!!!
不管是分類算法,還是回歸算法,要想讓算法訓(xùn)練出最精準(zhǔn)的模型,最重要的就是需要足夠的數(shù)據(jù)。
a/b/-c/d。。。是這個模型中的參數(shù),它們一開始都沒有固定的值,是在算法收集到足夠的數(shù)據(jù)后才會推算出來他們的數(shù)值。
當(dāng)你開始推送廣告之后,F(xiàn)acebook的算法還沒有任何數(shù)據(jù)(或者是它的數(shù)據(jù)庫里的有限的自有數(shù)據(jù)),它只是試探著,在你選擇的target audience里面隨機(jī)地推送廣告。
一旦某個用戶有了相應(yīng)的反饋,比如給廣告點(diǎn)贊、或者點(diǎn)擊了購買鏈接,F(xiàn)acebook會將該用戶的數(shù)據(jù)收集入你的數(shù)據(jù)庫里。
如果我們只有零散的幾個數(shù)據(jù),得到的擬合結(jié)果也會比較簡單,甚至?xí)a(chǎn)生過擬合(overfitting)。
簡單說就是很容易被一些特例的數(shù)據(jù)影響,而無法準(zhǔn)確找到更加通用的擬合曲線。
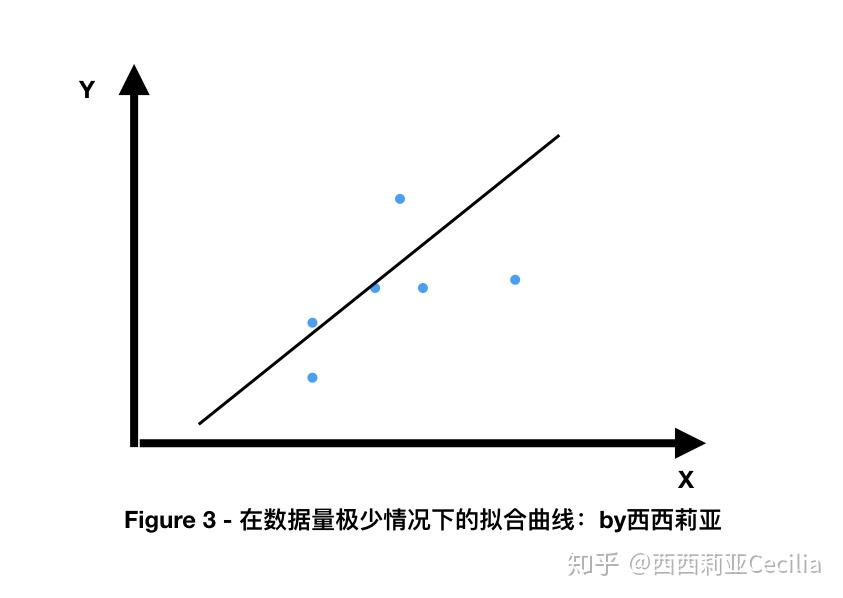
數(shù)據(jù)越多,越容易找到這些離散的點(diǎn)之間的相似性,從而對新的數(shù)據(jù)進(jìn)行更加準(zhǔn)確的預(yù)測。
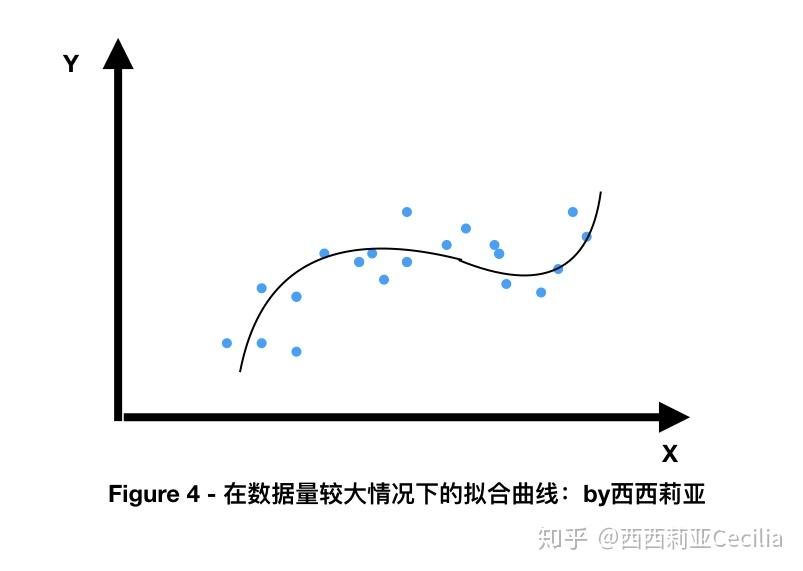
所以,聰明的童鞋們四不四已經(jīng)恍(早)然(知)大(如)悟(此),如果我們得到的數(shù)據(jù)足夠多(花的錢足夠多),我們就會得到大量在多維宇宙里如群星般散落的點(diǎn)。
這個時候會不會有人說,你說的不是廢話嘛?誰不知道廣告就是要多花錢。
《奇葩說》有一期黃執(zhí)中在辯論中講到:
“真實(shí)的世界,是由一連串隨機(jī)、混沌、細(xì)小的決策,以及漫長的因果鏈所組成的。一只蝴蝶煽動翅膀,可以在遠(yuǎn)方引起風(fēng)暴。”
我想說,在廣告屆這個理論也是成立的。
在廣告主最初選擇的一個target audience之后,F(xiàn)acebook Ads的算法其實(shí)是隨機(jī)的開始選擇初始受眾。
在得到一個最初的模型之后,算法會嘗試著尋找和這些用戶有相似特性的其他用戶、并且推送相同的廣告來反復(fù)確認(rèn)自己的判斷。
如果結(jié)果不符合預(yù)期,算法就會調(diào)整策略,比如調(diào)整某個特性的權(quán)重。
在這個調(diào)整的過程中,有可能會影響到廣告主的決策。
比如你的完美受眾可能是20~25歲的女生,但是你一開始并沒有對年齡做任何的限制,而Facebook根據(jù)它已有的數(shù)據(jù)可能就“猜測”35~40歲的受眾比較理想。
結(jié)果跑了幾天,廣告效果很差,沒有耐心的人有可能就此打住,終止廣告。
其實(shí)你再堅持一下,就可以“看到明天的太陽了”。。。啊不對。。是算法可能就找到更理想的受眾了。
因?yàn)殡S機(jī)性,導(dǎo)致決策的變化,從而影響整個數(shù)字營銷的效果。
數(shù)據(jù)不會說謊,但是片面的數(shù)據(jù),會誤導(dǎo)我們的判斷能力。
接下來,西西莉亞就和大家討論一下,如何降低這些偶然性和不確定性。
4 所以。。。我們應(yīng)該?
說了這么多,到底要怎么做,才可以避免被一些算法的不確定性影響廣告投放的效果呢?
西西莉亞在這里列幾點(diǎn),是我目前能想到的、也是最容易做到的、廣告投手可以注意到的事項(xiàng):
4.1 -?保證足夠的budget
我們已經(jīng)知道,算法的本質(zhì)就是尋找數(shù)據(jù)之間的關(guān)聯(lián)和共性,所以簡單來講,數(shù)據(jù)越多越好。
但是到底要多少數(shù)據(jù)才夠呢?
很遺憾告訴大家,這并沒有一個“定量”。
“大數(shù)據(jù)”的5V特征包括:大體量(Volume),多樣性(Variety),高速度(Velocity),準(zhǔn)確性(Veracity)、稀缺性(Value)。
但是到底多“大”才能被稱為大數(shù)據(jù),學(xué)術(shù)界并沒有統(tǒng)一的定義。
同理,到底多少廣告數(shù)據(jù)才夠,也只能見仁見智了。
Facebook官方文檔說,至少25~50次轉(zhuǎn)化才建議優(yōu)化。這應(yīng)該是差不多訓(xùn)練算法需要的數(shù)據(jù)的最少要求了。
西西莉亞建議大家量力而行。根據(jù)自己的能力決定一個初始預(yù)算,制定相應(yīng)的KPI。
如果廣告投放的效果沒法達(dá)到自己的預(yù)期目標(biāo),那就調(diào)整預(yù)算或者KPI。如果一直入不敷出就可以嘗試停掉這個campaign,改變廣告的素材或者調(diào)整受眾,重新投放。
不用擔(dān)心之前投放的錢打了水漂了,你之前花掉的那些錢相當(dāng)于跟Facebook買了數(shù)據(jù)。
Facebook會保存數(shù)據(jù)180天,這意味著180天之內(nèi)你的數(shù)據(jù)都可以被算法所用。
4.2 - 加快廣告的投放速度
理論上來講,同一個campaign,如果你的預(yù)算是1000刀,那么每天10刀持續(xù)投放100天和一天之內(nèi)全部花掉1000刀買到的數(shù)據(jù)的數(shù)量一樣。
實(shí)際上,如果算法決定了某個受眾是你的廣告的完美受眾,決定是否投放給TA還需要由很多別的因素決定。
比如廣告的Quality Score,又比如競價(Auction)算法。
高質(zhì)量的受眾和數(shù)據(jù)誰都想要,當(dāng)然就是出價高者得咯!
尤其是對于“購買轉(zhuǎn)化”為目標(biāo)的廣告,本來受眾的價格平均來說就很高。如果你的出價低于平均水平,F(xiàn)acebook只能幫你找到一些質(zhì)量比較低的leads。
遲遲得不到轉(zhuǎn)化,相當(dāng)于就得不到有效的數(shù)據(jù),算法就“巧婦難為無米之炊”。
再加上Facebook存儲數(shù)據(jù)有時間限制,西西莉亞建議,與其每天10刀連續(xù)投放100天地“擠牙膏”,倒不如一次性地投入1000刀,得到大量優(yōu)質(zhì)數(shù)據(jù)。
之后再用這些買到的數(shù)據(jù),進(jìn)行“再營銷(Re-targeting)“和建立“相似受眾(Look Like Audience)”,理論上來講,效果會好得多。
4.3 - 不要頻繁地改變投放策略
很多沒有耐心的童鞋,廣告放出去一兩天,看到?jīng)]有效果就坐不住了,想立刻改素材或者改受眾。
可是。。。心急吃不了臭豆腐啊喂!
我了解大家的心情,感覺每一分鐘money都在不停地嘩嘩地往外流,heart疼的要死。
可是作為專業(yè)的廣告投手,當(dāng)然要有看的更長遠(yuǎn)的眼光和能力啦!
你要轉(zhuǎn)化思維,想象這些錢都換成數(shù)據(jù)嘩嘩嘩地流回到你的帳戶里。╮( ̄▽ ̄"")╭
算法也是需要數(shù)據(jù)才可以訓(xùn)練出穩(wěn)定的投放模型哪!
特別是一開始,從無到有的積累過程,算法是及其不穩(wěn)定的(Facebook廣告算法的Learning phase)。
要是一有波動就調(diào)整策略,很可能會“誤殺”有潛力的廣告,白白浪費(fèi)掉一些數(shù)據(jù)。
所以廣告投放也要做好“放長線釣大魚”的心理準(zhǔn)備,通過觀察長期的數(shù)據(jù)曲線變化來做出更實(shí)際的預(yù)測和更合理的調(diào)整。
Facebook廣告的算法不斷地經(jīng)過海量數(shù)據(jù)的洗禮,要對它的智能有信心啊。
4.4 - 獲取盡量精準(zhǔn)的數(shù)據(jù)
算法的訓(xùn)練需要數(shù)據(jù),可是數(shù)據(jù)和數(shù)據(jù)也是不一樣的哦!
最簡單的例子,對于不同的投放目標(biāo)(objective), 獲取數(shù)據(jù)的難易程度也是不一樣的。
如果只是簡單的PPE,F(xiàn)acebook廣告算法知道哪些受眾最可能和廣告產(chǎn)生互動,它自己的數(shù)據(jù)庫里就有需要的數(shù)據(jù)。
但是如果是購買轉(zhuǎn)化(Purchase Conversion),這些數(shù)據(jù)只能來自于你的網(wǎng)站。
有很多人說,就算沒有任何初始數(shù)據(jù),也可以直接投放轉(zhuǎn)化廣告。
在之前的文章中,西西莉亞反復(fù)提及,F(xiàn)acebook廣告的目標(biāo)是“沖動型消費(fèi)者”。
所以就算不是同一個business或者產(chǎn)品,沖動型消費(fèi)者們也會有一些共通的特質(zhì)。
Facebook可以在你的target audience里找到之前有過購買經(jīng)驗(yàn)的人,以他們的數(shù)據(jù)作為訓(xùn)練集。
但是Facebook并不鼓勵這樣做。
每一個廣告和產(chǎn)品都(應(yīng)該是)獨(dú)一無二的。
如果你用別的產(chǎn)品的數(shù)據(jù)來訓(xùn)練另一個產(chǎn)品的推送算法,弊端就是價格貴,數(shù)據(jù)少、甚至有偏差。
當(dāng)然如果您是土豪,當(dāng)我沒說。只要能出得起價,總是能買到足夠的優(yōu)質(zhì)數(shù)據(jù)的。
類似的問題,還有比如是開一個“雜貨鋪”還是某一個精準(zhǔn)的“niche”的網(wǎng)店。
越是精準(zhǔn)的niche,在數(shù)據(jù)體量相同的條件下,流量純度會越高,對算法的訓(xùn)練越有利。
比如一個“雜貨鋪”之前是賣牙齒美白產(chǎn)品,現(xiàn)在又開始賣釣魚鉤,兩個完全不搭旮的niche。
就算之前已經(jīng)有了很多的購買量,但是這些數(shù)據(jù)可能在訓(xùn)練“魚鉤廣告”的模型中就不好使。
但是這些問題也是可以通過對數(shù)據(jù)分類克服的。
你可以在自己的數(shù)據(jù)“倉庫”里,設(shè)置一個“牙齒美白購買者”的類別,和一個“釣魚愛好者”的類別。在投放廣告的時候,使用相應(yīng)組別的數(shù)據(jù)就OK。
當(dāng)然,也不排除不同niche的消費(fèi)者之間會有相似的特性,說什么也不如真金白銀跑幾組廣告試試。
5 事物的兩面性
總有人說Facebook廣告越來越不好做了,西西莉亞希望大家還是要努力看到好的一面啊。
雖然廣告越來越貴,競爭越來越激烈,可是同時機(jī)器學(xué)習(xí)的算法也越來越智能呀!
最開始的時候,F(xiàn)acebook的受眾特征(Demoraphics)只有可憐的幾個性別啊、地址什么的。看看今天,有多少個興趣特征等著你去target!
無數(shù)的廣告主在Facebook投放的廣告,也在不斷地幫助Facebook改進(jìn)算法、篩選精準(zhǔn)受眾。這對于后入場者,也算是一種福利嘛!
再說了,西西莉亞一直以來的信念就是,做好產(chǎn)品更重要。好的產(chǎn)品是會自己說話的,廣告只是幫助它把信息傳達(dá)給需要的人。
所以最后正能量一波:好好做產(chǎn)品,好好做營銷。
Keep Calm and Run The Ads!
Ending:
Facebook廣告的受眾推送機(jī)制是不對外公開的。
算法就像一個黑盒,你只知道你的輸入(設(shè)置預(yù)算,和設(shè)置target audience),然后通過廣告算法的輸出(impression數(shù)/點(diǎn)擊數(shù)/視頻觀看數(shù)/轉(zhuǎn)化數(shù)。。。等等)來評估和調(diào)整自己的投放策略。
本文是西西莉亞結(jié)合自己的課題經(jīng)驗(yàn)、以及搜索相關(guān)領(lǐng)域的論文而作出的分析。
會有一些主觀的猜測和觀點(diǎn),主要是希望和大家一起探索這個“黑盒”內(nèi)部的工作機(jī)制。
如果能給大家一些不一樣的思考角度,西西莉亞也就覺得是功勞一件啦!筆芯~?
END
作者:西西莉亞 來源:西西莉亞的營銷筆記
本文為作者獨(dú)立觀點(diǎn),不代表出海筆記立場,如若轉(zhuǎn)載請聯(lián)系原作者。